
PRAESENTIA
[패스트캠퍼스] Ch2. 자산배분 모델링 - 2 본문
6. 분산투자(횡적 배분 모형)

- MVO(평균-분산 최적화) 모형의 한계
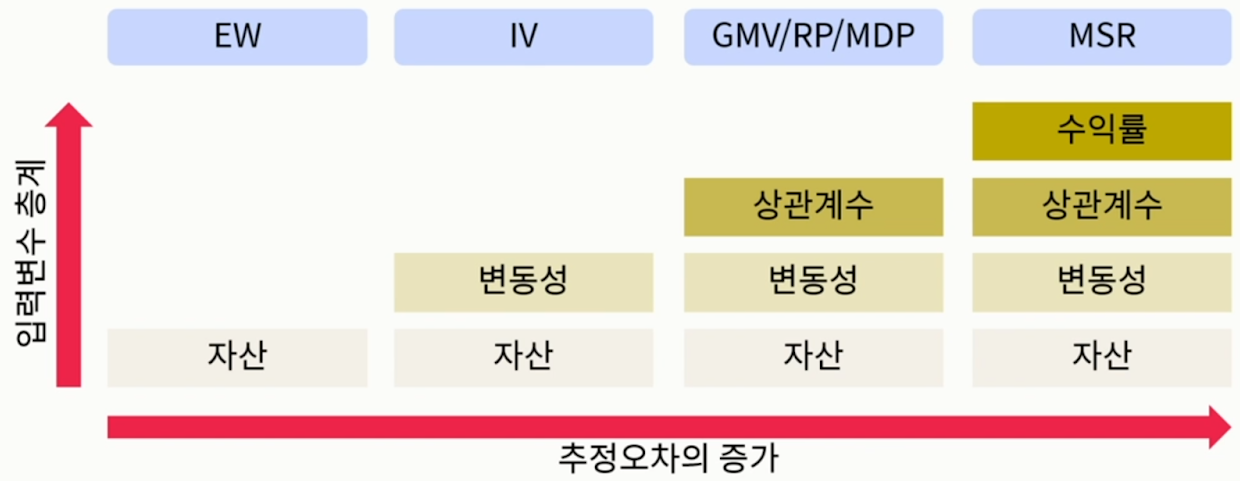
- 추정해야 하는 입력 변수 개수가 많아질수록 알고리즘 안정성은 훼손됨
- 가장 처음 제시되었던 MVO 모형(=MSR)이 역설적으로 복잡도가 가장 높은 모델인 셈(MVO의 입력변수로 수익률, 변동성, 상관계수가 전부 필요하기 때문)
- EW: Equal Weight, 동일 가중으로 전체 자산에 투자하는 모형, 제일 심플한 층계
- IV: Inverse Volatility(=EMV), 자산들의 변동성 값만 알면, 변동성이 낮은 자산에 더 많은 비중으로 투자하는 모형
- GMV/RP/MDP: 공분산 데이터만 필요한 모형들
- 동일가중 모형(EW)
- 모든 자산에 동일 가중치를 줘서 포트폴리오를 구성
- 샤프비율 최대화 모형(MSR, MVO)
- 수익률 벡터와 공분산 행렬을 입력변수로 받아서, 샤프비율을 최대화 하는 최적화 문제
- 코너 해(Corner Solution) 문제가 자주 발생: 한두 종목에 편중되는 현상
- 즉, 변동성에 굉장히 취약한 셈, 포트폴리오의 장점이 사라짐
- 코너해가 발생하는 이유는 입력변수가 너무 많아졌기 때문
- 최소 변동성 모형(GMV, Global Minimum Variance)
- MSR과 마찬가지로 얘도 코너해 현상이 자주 발생
- 변동성을 줄이려니 당연히 리스크 높은 자산은 피할 수밖에 없게 됨
- 선택 가능한 모든 포트폴리오 집합 중, 변동성이 가장 낮은 전략(최적화)
- 입력 변수로는 공분산 행렬만 사용(수익률 데이터 불필요)
- 모형 특성상 return 값이 낮음
- 최대 분산투자 모형(MDP, Most Diversified Portfolio)
- 분산투자의 효과를 극대화 하는 전략, 상관계수에 방점을 둔 전략
- 최적화 문제: 분산비율(DR, Diversification Ratio)의 최대화

분산이 얼마나 되어 있는지 측정하는 지표 - 분모는 포트폴리오 전체의 분산, 분자는 상관계수가 빠진 개별 자산들의 분산. 즉, 분자는 모든 자산의 상관계수가 0이라 가정하고서 계산한 분산의 합.
- 그래서 분모를 줄이는 게 중요. 분모를 줄이려면 상관계수를 낮춰야 함. 즉, 자산 간의 상관계수가 마이너스인 애들 위주로 구성해야 DR이 극대화
- 입력 변수는 공분산 행렬 & 변동성 벡터임. 그런데 변동성 벡터가 공분산 행렬에 포함되어 있으므로 사실상 하나만 입력 변수.
- 리스크 버짓팅 모형
- 위험 예산(Risk Budget): 포트폴리오 전체 위험의 몇 퍼센트를 해당 자산이 가져갈 것인가?
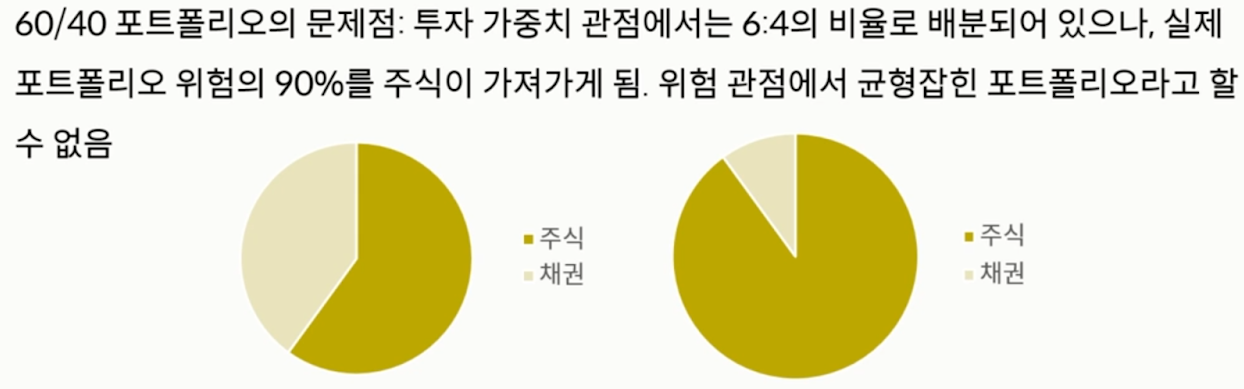
- 포트폴리오의 위험을 결정하는 건 자산의 변동성과 상관계수 뿐
- 따라서 MVO 기반의 모델과 다르게, 자산의 기대수익률을 추정할 필요 없음
- 해당 컨셉으로부터 뒤에 리스크 패리티 모형과 역변동성 모형이 파생됨

- 자산(wi)이 전체 포폴 리스크(R)의 기여도를 편미분으로 계산, 거기에 비중을 다시 곱해줘서 전체 리스크 중 특정 자산에 할당되어야 하는 위험 기여도를 계산

- 위험 예산 할당치(TRC)를 포트폴리오 변동성으로 나눠줌. 여기서 Si는 고정 상수이고, Wi인 가중치를 조정해서 S에 맞춰야 함. 사실상 최적화 문제를 푸는 셈
- 위험 예산(Risk Budget): 포트폴리오 전체 위험의 몇 퍼센트를 해당 자산이 가져갈 것인가?
- 리스크 패리티 모형(RP)
- 각 자산의 위험 기여도를 동일하게 1/N로 가져가는 포트폴리오, 자산별 위험 예산과 동일 비중 간 괴리를 최소화 하는 전략

- 가중치 관점에서 균형이 EV라면, 리스크 관점에서 균형 전략은 RP
- 입력변수로는 공분산 행렬만 필요
- 코너해 현상이 리스크 패리티 전략에서는 거의 일어나지 않음. 어지간하면 다 일정 가중치를 가져감
- 각 자산의 위험 기여도를 동일하게 1/N로 가져가는 포트폴리오, 자산별 위험 예산과 동일 비중 간 괴리를 최소화 하는 전략
- 역변동성 모형(IV or EMV)

- 자산간 상관계수를 0이라고 가정하고서, 각 자산의 위험 기여도를 동일하게 만들어주는 전략
따라서 입력변수는 ‘변동성’ 하나뿐임.
- 블랙-리터만 모형
- 블랙-리터만 모형: 시장의 뷰와 투자자의 뷰를 결합한 방식의 포트폴리오 구성법
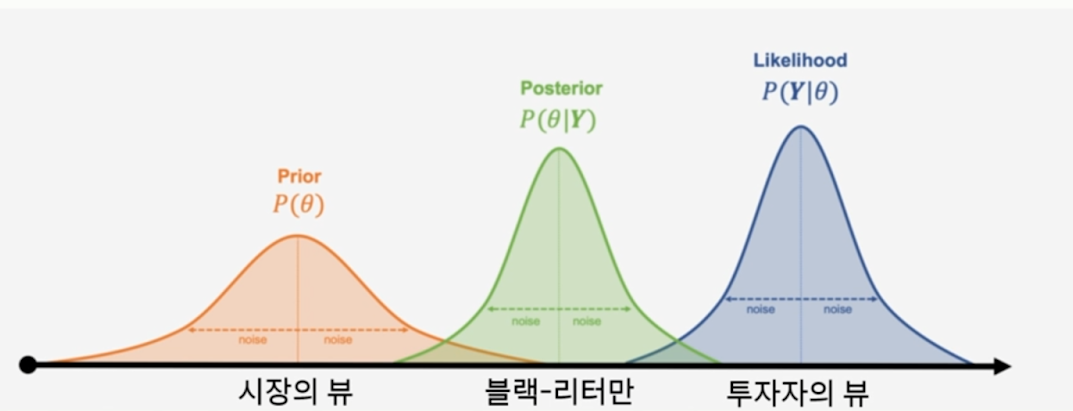
베이지안 통계 접근법 
MVO와 블랙리터만 모델의 비교
- 베이즈 정리
- 한줄 요약: 현실에서 얻은 데이터로 미래를 예측(현재의 현상이 미래에도 지속)
- 블랙 리터만 모형 프로세스
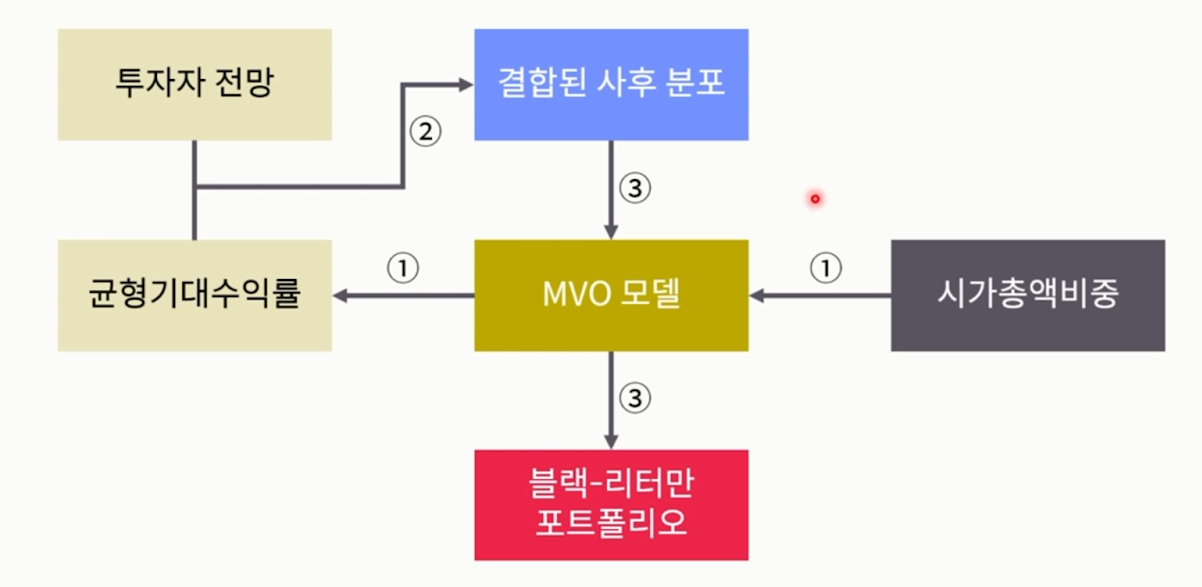
- 1. 시장 사전 분포를 정의
- 자산별 시가총액 비중을 토대로 MVO모델 인버스에 인풋, 이를 토대로 시장이 각 자산마다 어느 정도의 수익률을 기대하는지 도출하는 것(리버스 엔지니어링)
- 기존의 MVO 모델은 반대임. 기대수익률을 인풋으로 집어넣어서 비중을 산출하는 거였는데, 블랙리터만에서는 이를 역으로 활용하는 셈
- 2. 투자자의 뷰 설정
- 이 기대수익률에 투자자의 뷰를 합쳐서 사후 분포를 도출.
- 3. 시장 뷰와 투자자 뷰를 결합한 사후 분포 도출
- 그 사후 분포를 다시 MVO에 집어넣어서 모델을 업데이트 함
- 4. 블랙-리터만 포트폴리오 산출
- 그럼 최종적으로 블랙 리터만 포폴이 산출됨
- 리버스 엔지니어링
- 가정: 시가총액은 시장균형을 이룬 투자 비중이다.
- CAPM으로 시장에 내재된 균형 기대수익률 도출, 이를 활용해 자산별 균형기대수익률을 역산

여기서 람다는 시장 전체의 샤프 비율
- 투자자 전망
- 투자자 전망은 둘로 나뉨
- 절대적 전망: 단일 자산에 대한 전망
- 상대적 전망: 두 자산에 대한 상대적 성과 전망

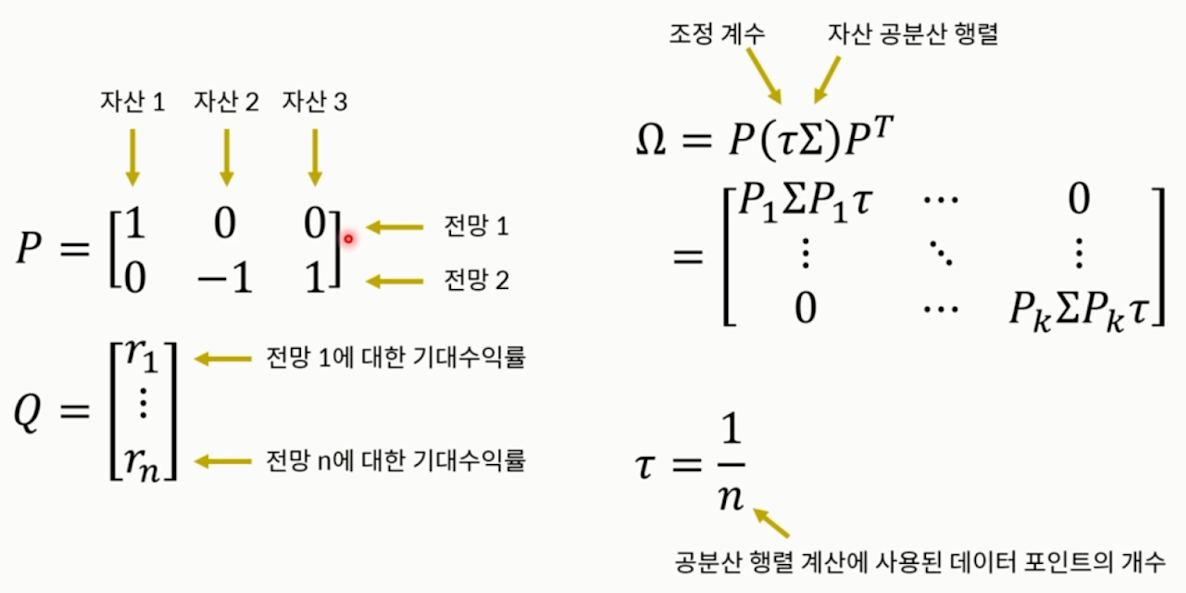
- P에서 전망1은 절대적 전망, 전망 2는 상대적 전망
- Q에 각 전망별 기대수익률이 들어감
- 투자자 전망은 둘로 나뉨
- 블랙-리터만 모형: 시장의 뷰와 투자자의 뷰를 결합한 방식의 포트폴리오 구성법
- 총정리
7. 안전마진

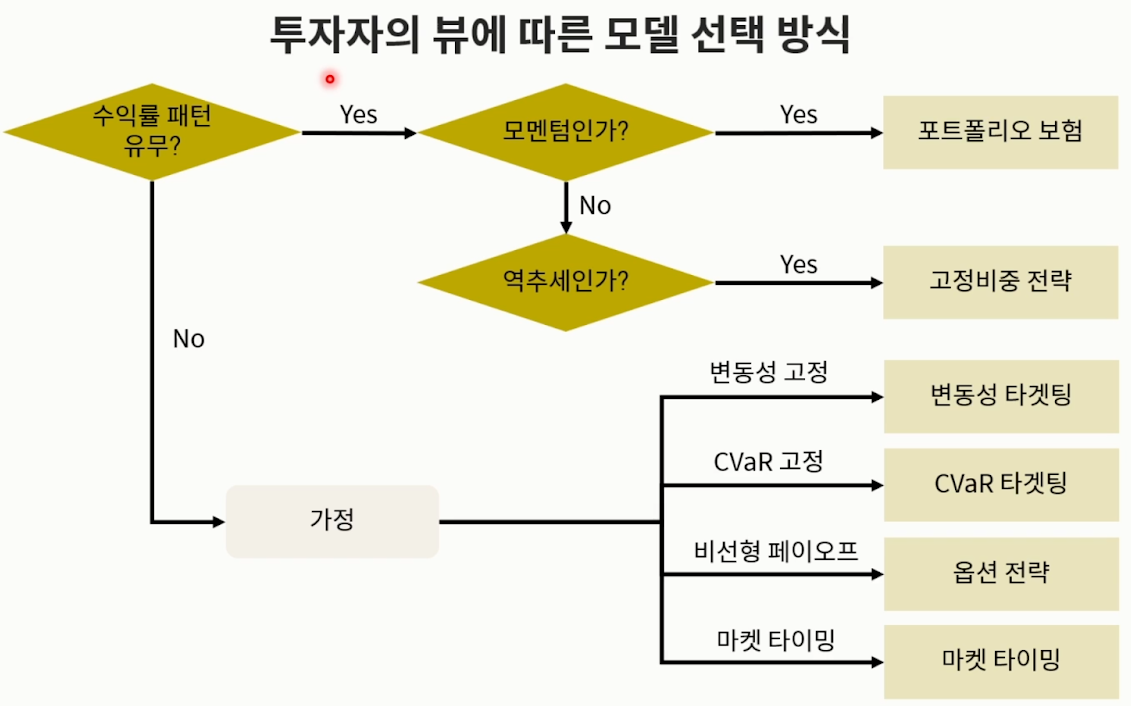
- 해당 챕터는 ‘종적 배분 모형’에서 현금 비중을 정하는 파트
- 크게 4종류를 다룰 예정
- 변동성 타겟팅 / CVaR 타겟팅 / 켈리 베팅 / 포트폴리오 보험
- 변동성 타겟팅(VT, Volatility Targeting)
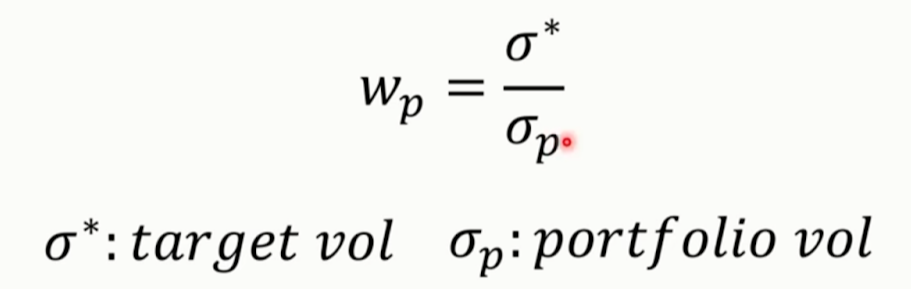
- 포트폴리오의 가중치가 현재 변동성에 반비례하여 동적으로 조정
- 목표 변동성과 과거 포트폴리오의 변동성을 산출하여 가중치를 설정함
- CVaR 타겟팅(CVT)
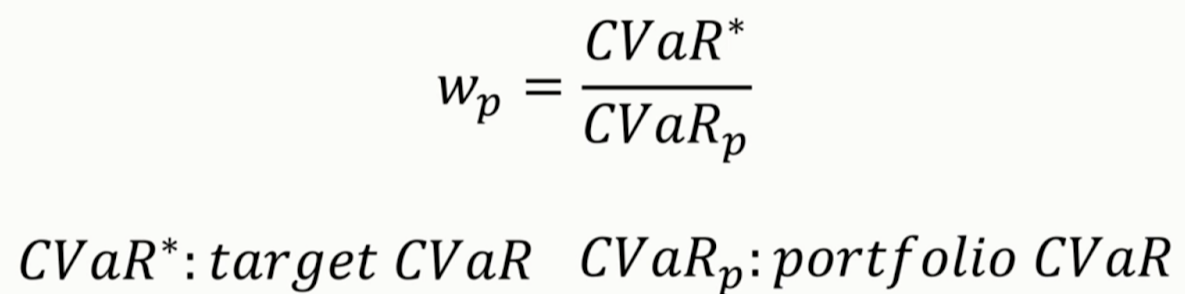
- 목표 CVaR 값을 과거 포트폴리오의 CVaR 값으로 나눠서 산출
- 즉, CVaR 값에 반비례하여 가중치 설정
- 변동성 타겟팅보다 CVaR 타겟팅이 더 보수적인 경향이 있음(bet size도 작은 편)
- 켈리 베팅
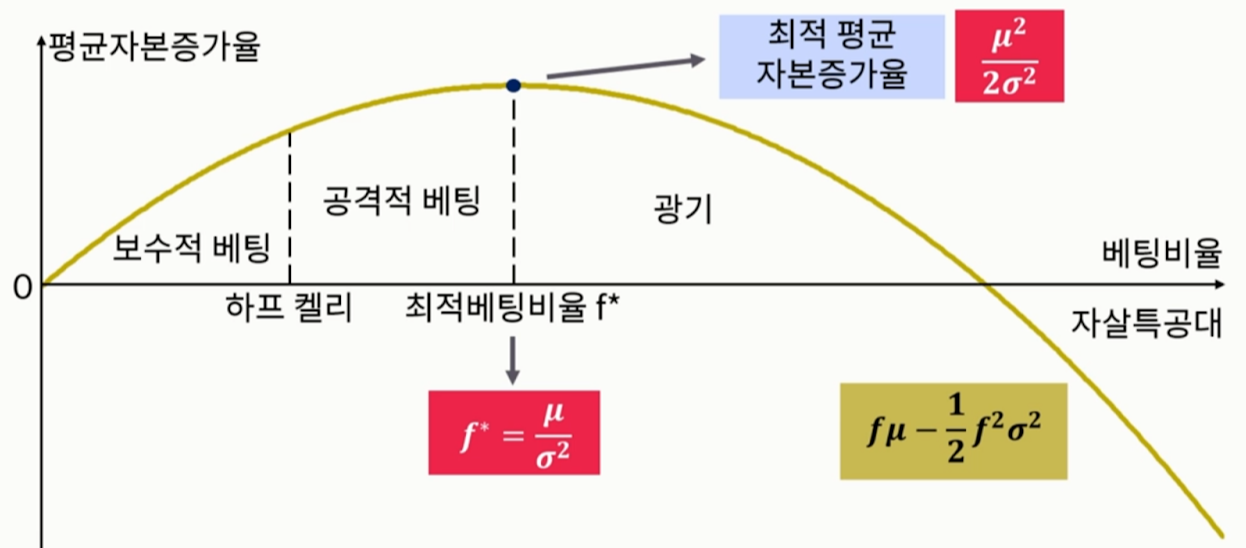
- 켈리 공식: 포트폴리오의 수익률을 분산으로 나눈 값으로 포트폴리오 가중치를 결정
- 위 식에서는 f가 베팅 사이즈. 이걸 어떻게 설정해야 최대 수익인지 도출
- 다만, 시장 변화에 따라 노이즈가 있을 수 있기 때문에, 그 f*에 절반에 해당하는 ‘하프 켈리’도 제안. 즉, 하프 켈리는 좀 더 보수적인 투자안.
- 그런데 이 켈리 공식은 카지노에서 도출되었기 때문에, 금융 시장에 그대로 도입하기는 조심스러움
- 그래서 위 공식대로 f를 계산하면 변동성이 지나치게 큼. 때문에 수정 켈리 베팅이 제안됨
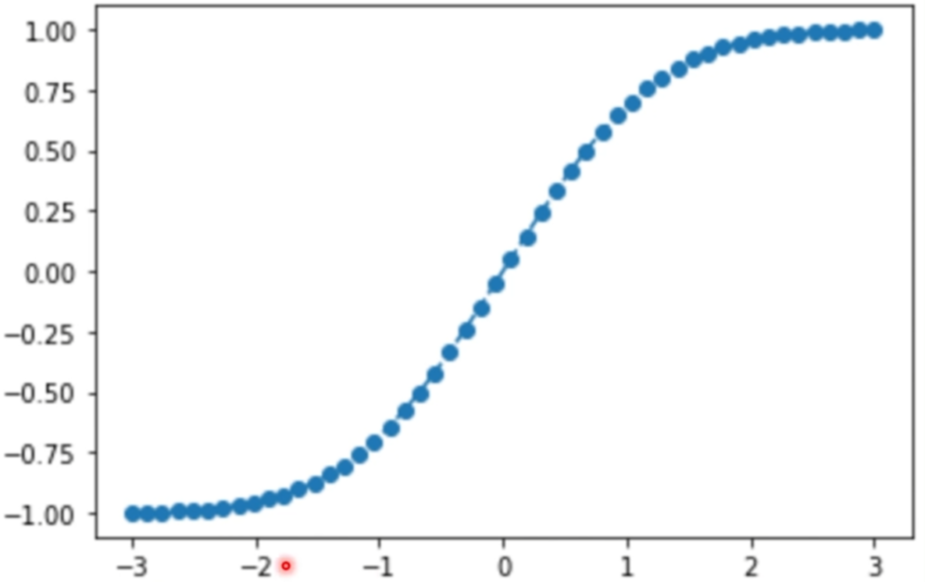
- 수정 켈리 베팅:
- 샤프 비율(w_p)을 1차로 계산, 그걸 N(CDF), 누적분포함수에 넣어서 가중치를 계산
- 가로축이 샤프비율, 세로축이 수정된 켈리 베팅 사이즈. 즉, 샤프비율이 높을수록 롱, 마이너스일수록 숏
- 포트폴리오 보험(CPPI, Constant Proportional Portfolio Insurance)
- ‘포트폴리오 쿠션’에 비례하여 투자 비중이 조정되는 종적배분 모델
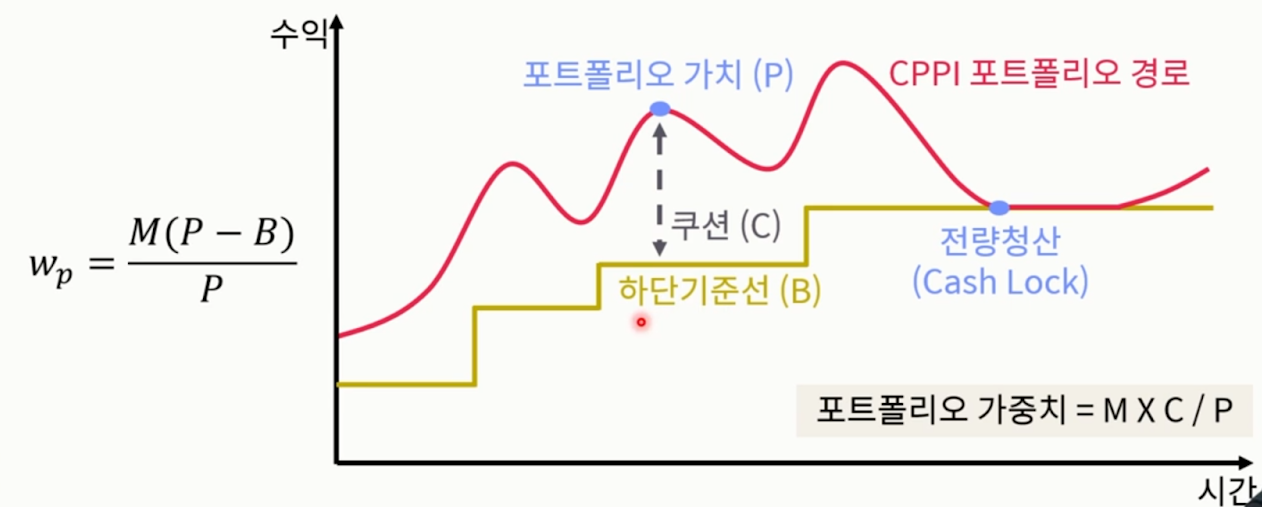
- 포트폴리오 쿠션: 현재 포트폴리오의 가치 - 하단기준선(손절라인)
- 쿠션이 커질수록 베팅 사이즈는 커지는 셈
- 이 계산을 하려면 M, P, B가 필요. P가 포트폴리오의 가치, B가 하단기준선이고, M은 레버리지 비율. 즉 M은 우리가 임의 설정 가능
- ‘포트폴리오 쿠션’에 비례하여 투자 비중이 조정되는 종적배분 모델
- 기타 방법론
- 옵션 기반 헤지 전략
- 옵션: 미래에 기초자산을 사거나 팔 권리를 지닌 파생상품
- 옵션 전략의 장점: 어떤 형태의 손익구조도 구현 가능(비선형 모델이라 가능)
- 옵션 전략의 단점: 보험 상품처럼 계속해서 프리미엄을 지급해야 함
- 옵션 기반 포트폴리오 보험 전략 예시: 베어 풋 스프레드, 칼라
- 마켓 타이밍
- 시장이 상승인지 하락인지를 맞춰 현금 비중을 결정하는 방법론
- 계량적으로나 주관적으로나 모두 접근 가능, 계량적 접근 방식이 사실상 팩터 포트폴리오의 시장 국면 분석과 같은 맥락(chap.3에서 나옴)
- 옵션 기반 헤지 전략
- 종합 정리
8. 위험관리 및 위험지표
- 정의가능 리스크 vs. 정의불가능 리스크
- 인지 가능 리스크: 계량화와 측정이 가능한 리스크
- Ex. VAR, CVaR 등
- 정상적인 상황에서의 리스크
- 인지 불가능 리스크: 측정 불가한 리스크
- 블랙 스완이라고 함
- 리스크 모형을 만들 수 없고 해석 불가
- 인지 가능 리스크: 계량화와 측정이 가능한 리스크
- 리스크의 종류

- 시장리스크
- 가격 변동에 의한 리스크, 최적화 모델이 상정하는 위험
- 모델 리스크
- 모형 자체의 오류에 의한 리스크, 데이터의 퀄리티나 통계적 모델의 비적합성
- 신용 리스크
- 거래상대방에 의한 리스크, 장외거래에서 주로 발생 가능
- 운영 리스크
- 결제 및 청산 관련 리스크, 법적 문제도 여기에 포함
- 여러 위험 지표

- 실무에서 가장 많이 쓰이는 리스크 지표 4가지
- 하방 표준편차(손실 표준편차)
- 손실이 난 경우만 고려했을 때의 표준편차
- 수익이 난 구간은 전부 0으로 처리하여 계산
- VaR(Value at Risk)
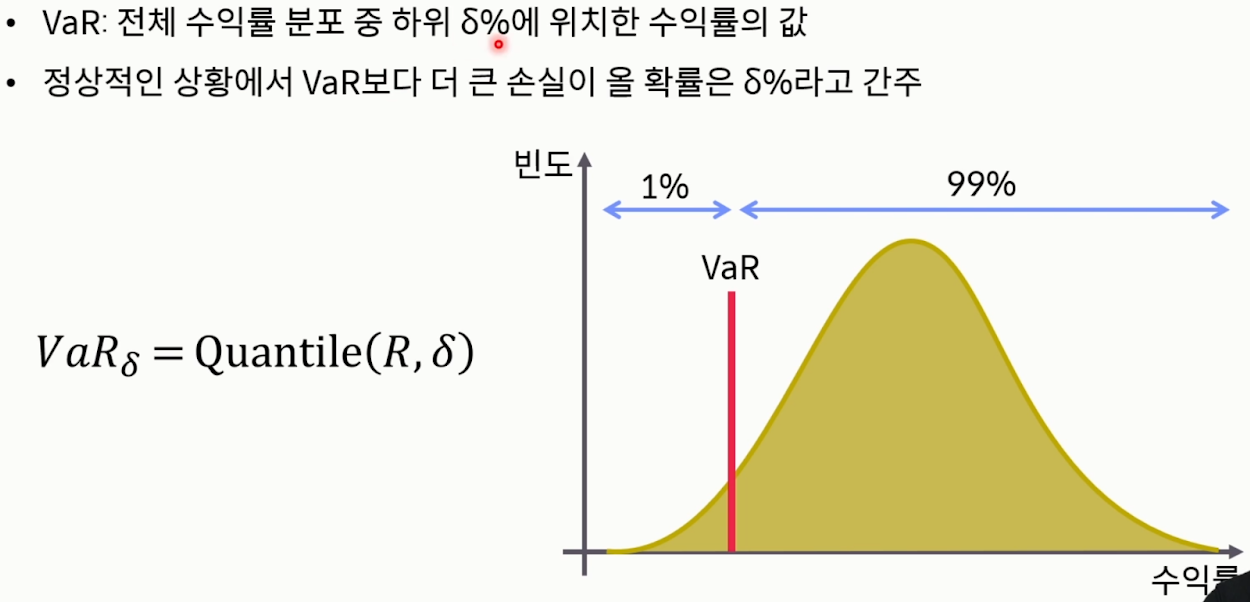
- 최대예상손실액
- 정상적인 시장 상황에서 VaR보다 더 큰 손실이 발생할 확률을 N%로 가정(보통 N은 1~5 사이로 정함)
- CVaR(Conditional VaR)
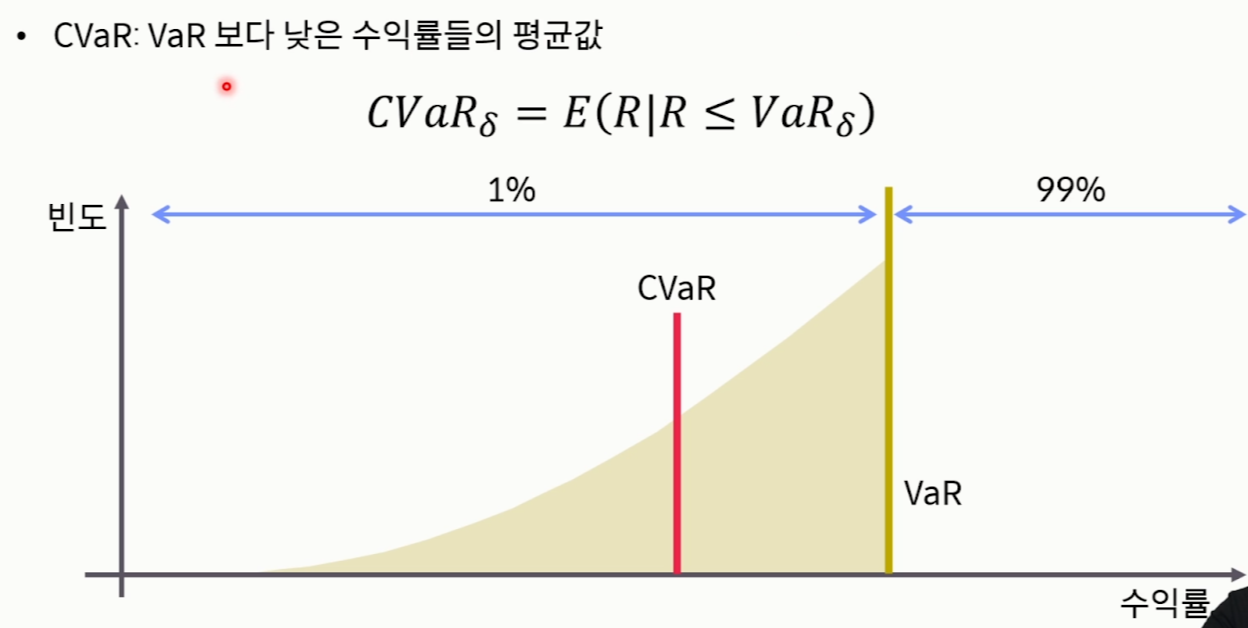
- 조건부최대예상손실액
- VaR보다 더 낮은 수익률들의 평균값, VaR보다 보수적
- VaR 한계 기여도
- 개별 자산이 전체 포트폴리오 VaR에 얼마나 기여하는지 측정하는 지표
- 리스크 버짓팅 모형에서 다뤘던 ‘포트폴리오 위험 기여도’ 개념과 같은 맥락

- MVC: 어떤 자산 i의 가중치가 한 단위 변했을 때, 포트폴리오 VaR 변화에 대한 민감도
- TVC: 현재 포트폴리오 전체 VaR 중 자산 i가 차지하는 비중
- 개별 자산이 전체 포트폴리오 VaR에 얼마나 기여하는지 측정하는 지표
- CVaR 한계 기여도
- CVaR 한계 기여도: 전체 포폴 CVaR에서 특정 자산이 차지하는 비중
- VaR와 마찬가지로 MCC, TCC 정의
- 스트레스 테스트와 시나리오 분석
- 시나리오 분석: 특정 시장 상황을 가정하고, 포트폴리오 성과를 측정해보는 방법
- 최악을 가정하기에 잠재적으로 인지 불가능한 위험을 고려해볼 수 있음
- 역사적 스트레스 테스트
- 시나리오 분석의 한 케이스
- 역사적 사례에 기반하여 과거 데이터를 테스트 해보는 것(ex. 1987 블랙 먼데이, 2008 서브프라임, 2020 코로나)
- 과거 데이터가 존재하지 않는 경우, 자산간 상관계수를 통해 간접적으로 테스트 가능
- 주관적인 시나리오 상황
- 실제 발생한 일은 아니어도, 규제 당국이나 리스크 관리 부서에서 상정한 시나리오로 테스트 수행
- 시장 변수 움직임의 극단적 설정이 가능
- ex) 유가 50% 상승, 환율 3표준편차 돌파 등
- 시나리오 분석: 특정 시장 상황을 가정하고, 포트폴리오 성과를 측정해보는 방법
- VaR & CVaR의 계산
- 역사적 방법
- 비모수적 방법, 순전히 과거 데이터로만 추정
- (위에서 했던 과거 데이터 기반의 계산식이 여기에 해당됨)
- 공분산 방법(델타노말 방법)

- 모수적 방법, 과거 데이터를 기반으로 분포의 파라미터를 추정하여 계산
- 실제 데이터로 정규분포의 모수(뮤, 시그마)를 추정, 그걸로 위험지표를 계산
- 시뮬레이션 방법
- 분포를 기반으로 가상 경로를 생성해 시뮬레이션을 계속 돌림(몬테 카를로 시뮬레이션)
- 몬테 카를로 시뮬레이션: 반복된 무작위 추출로 함수 값을 근사시키는 알고리즘
- 1차로 모수를 추정하고, 2차로 그 모수로 난수를 생성하여 수많은 시뮬레이션 실행

- 역사적 방법
'퀀트 공부 > 금융공학' 카테고리의 다른 글
| [패스트캠퍼스] Ch3. 팩터모델링 - 2 (1) | 2023.05.12 |
|---|---|
| [패스트캠퍼스] Ch3. 팩터모델링 - 1 (1) | 2023.05.11 |
| [패스트캠퍼스] Ch2. 자산배분 모델링 - 1 (1) | 2023.05.09 |
| [패스트캠퍼스] Ch1. 퀀트 비즈니스 실무 - 2 (0) | 2023.05.08 |
| [패스트캠퍼스] Ch1. 퀀트 비즈니스 실무 - 1 (0) | 2023.05.07 |
'퀀트 공부/금융공학' Related Articles
more




Comments